During last Spark+AI Summit Europe 2019 I had a chance to attend a talk from Miguel Martinez who was presenting Rapids, the new Open Source framework from NVIDIA for GPU accelerated end-to-end Data Science and Analytics.

Rapids is a suite of Open Source libraries:
I enjoied the presentation and liked the idea of this initiative, so I wanted to start playing with the Rapids libraries in Python on Colab, starting from cuDF, but the first attempt came with an issue that I eventually solved. So in this post I am going to share how I fixed it, with the hope it would be useful to someone else running into the same blocker.
I am assuming here you are already familiar with Google Colab. I am using Python 3.x as Python 2 isn't supported by Rapids.
Once you have created a new notebook in Colab, you need to check if the runtime for it is set to use Python 3 and uses a GPU as hardware accelerator. You can check and eventually set it from the toolbar menu Runtime -> Change runtime type. Then you have to check that Colab has given you access to a NVIDIA Tesla GPU, as it is supported by Rapids. You can do this check from the notebook code by running
and look for the GPU type, as highligthed in figure 2:

The next step would be the installation of the cuDF library for CUDA 10.x. You can use pip from the notebook:
At the end of the installation, before importing the cuDF package, you need to do an extra setup that I am going to explain below. If you don't do it, any time you try to execute the cuDF API, you will receive the following misleading error:

The message states that the cudatoolkit isn't installed in your environment, so the numba package cannot be find, which isn't true, as cudatoolkit is already part of the Colab environment. The real root cause of this error is that the paths to the drivers are different in the runtime from what expected by the library. So you have to locate them first
and setup the environment accordingly
I have also put extra checks in case the paths shouldn't be found, which would probably be useless, but you never know :)
Now you can import cuDF, numpy and any other Python package you would need
and start playing with GPU Data Frames
Enjoy it!
I will share my impressions on this library and the others in Rapids as soon as I have completed some PoCs.

Fig. 1 - Overview of the Rapids eco-system
Rapids is a suite of Open Source libraries:
- cuDF
- cuML
- cuGraph
- cuXFilter
I enjoied the presentation and liked the idea of this initiative, so I wanted to start playing with the Rapids libraries in Python on Colab, starting from cuDF, but the first attempt came with an issue that I eventually solved. So in this post I am going to share how I fixed it, with the hope it would be useful to someone else running into the same blocker.
I am assuming here you are already familiar with Google Colab. I am using Python 3.x as Python 2 isn't supported by Rapids.
Once you have created a new notebook in Colab, you need to check if the runtime for it is set to use Python 3 and uses a GPU as hardware accelerator. You can check and eventually set it from the toolbar menu Runtime -> Change runtime type. Then you have to check that Colab has given you access to a NVIDIA Tesla GPU, as it is supported by Rapids. You can do this check from the notebook code by running
!nvidia-smiand look for the GPU type, as highligthed in figure 2:

Fig. 2 - The output of the nvidia-smi command in a Colab notebook
The next step would be the installation of the cuDF library for CUDA 10.x. You can use pip from the notebook:
!pip install cudf-cuda100At the end of the installation, before importing the cuDF package, you need to do an extra setup that I am going to explain below. If you don't do it, any time you try to execute the cuDF API, you will receive the following misleading error:
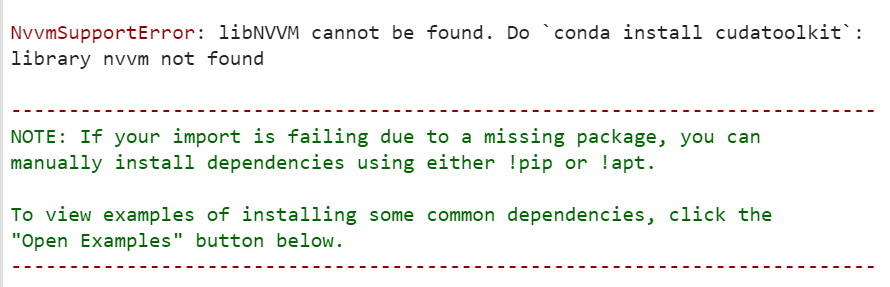
Fig. 3 - The error message in Colab when trying to use the cuDF API
The message states that the cudatoolkit isn't installed in your environment, so the numba package cannot be find, which isn't true, as cudatoolkit is already part of the Colab environment. The real root cause of this error is that the paths to the drivers are different in the runtime from what expected by the library. So you have to locate them first
dev_lib_path = !find / -iname 'libdevice'
nvvm_lib_path = !find / -iname 'libnvvm.so'and setup the environment accordingly
import os
if len(dev_lib_path) > 0:
os.environ['NUMBAPRO_LIBDEVICE'] = dev_lib_path[0]
else:
print('The device lib is missing.')
if len(nvvm_lib_path) > 0:
os.environ['NUMBAPRO_NVVM'] = nvvm_lib_path[0]
else:
print('NVVM is missing.')I have also put extra checks in case the paths shouldn't be found, which would probably be useless, but you never know :)
Now you can import cuDF, numpy and any other Python package you would need
import cudf
import numpy as np
...and start playing with GPU Data Frames
df = cudf.DataFrame()
...Enjoy it!
I will share my impressions on this library and the others in Rapids as soon as I have completed some PoCs.
Feedback from Miguel Martinez (NVIDIA): by installing cuDF using pip, you will get the release 0.61. In order to install a latter or the latest release you have to use conda onstead. Thanks Miguel for the heads up.
ReplyDeleteThis video helps me to understand Matplotlib whats your opinion guys.
ReplyDelete
ReplyDeleteI would like to thank you for this fantastic read!! DevOps Training in Bangalore | Certification | Online Training Course institute | DevOps Training in Hyderabad | Certification | Online Training Course institute | DevOps Training in Coimbatore | Certification | Online Training Course institute | DevOps Online Training | Certification | Devops Training Online
Nice blog, very informative content.Thanks for sharing, waiting for the next update…
ReplyDeleteWhy learn Python?
Why is Python so popular?
Pretty Post! Thank you so much for sharing this good content, it was so nice to read and useful to improve my knowledge as an updated one, keep blogging.
ReplyDeletePython Certification Training in Electronic City